Retrospective Dissertation - Part 2: Tornado Reports
Posted on Mon 06 July 2020 in retrodiss
In Part 1 of Retrospective Dissertation, we went over the data science problem we'll be tackling and why I'm masochistic enough to go through dissertation research again. In Part 2, we'll go over exploring the tornado report dataset from the Storm Prediction Center. This will be used to generate labels for our prediction model.
The Storm Prediction Center (SPC) provides both excellent severe weather forecasts and datasets of historical severe weather events. Their severe weather database files have observed severe weather reports dating back to 1950 for hail, wind, and tornado events, though we'll only be focusing on the tornado reports. There are some big caveats and limitations that come with the tornado reports dataset that we'll get into in this post, but it's a great public dataset that is constantly being updated.
0. Getting the Data
We want to use the csv file that represents "actual" tornado tracks, which provides single connected tracks as observations (as opposed to individual state reports). From the looks of it, the "actual" tornado reports dataset is still preliminary for 2017, so we'll keep that in mind. The csv file can be found at this link with headers included. That said, some of the column names aren't particularly descriptive, nor will we be using all of the columns. A document provided by SPC gives us information about what each column represents, so we'll be renaming and using the following columns:
yr->observation_year: The year the observed tornado occurred.mo->observation_month: The month the observed tornado occurred.dy->observation_day: The day of the month the observed tornado occurred.tz->timezone: The timezone for the observation date and time. The format doc from SPC says all observation dates and times (with the exception of unknown and GMT/UTC reports) have been converted to CST.st->observation_state: The state in which the observed tornado occurred.mag->f_or_ef_scale: The Fujita (F) or Enhanced Fujita (EF) scale magnitude of the tornado. This ranges from 0-5, with the EF scale applied to tornadoes after January 2007. Unknown F/EF scale values are marked as -9.slat->starting_latitude_deg: The starting latitude (in degrees) of the tornado track.slon->starting_longitude_deg: The starting longitude (in degrees) of the tornado track.elat->ending_latitude_deg: The ending latitude (in degrees) of the tornado track.elon->ending_longitude_deg: The ending longitude (in degrees) of the tornado track.
We'll be using pandas to get the tornado reports csv off of SPC's website, and will also be using the date and time columns to create a column of datetime objects:
rename_dict = {'yr': 'observation_year', 'mo': 'observation_month',
'dy': 'observation_date', 'tz': 'timezone',
'st': 'observation_state', 'mag': 'f_or_ef_scale',
'slat': 'starting_latitude_deg',
'slon': 'starting_longitude_deg',
'elat': 'ending_latitude_deg',
'elon': 'ending_longitude_deg'}
spc_tornado_url = "https://www.spc.noaa.gov/wcm/data/1950-2018_actual_tornadoes.csv"
tornado_df = (pd.read_csv(spc_tornado_url,
parse_dates={'observation_datetime': ['date', 'time']})
.rename(columns=rename_dict)
.loc[:, list(rename_dict.values()) + ['observation_datetime',]])
Ideally, we'd want our data in "tidy" format (which Tom Augspurger gives a great example of using pandas and tidy data), which is when our data meets the following criteria (per definition from Hadley Wickham):
- Each variable in our dataset forms a column.
- Each observation forms a row.
- Each type of observational unit forms a table.
Since we're only working with one kind of observational unit (tornado report), we can focus on the first two criteria. Looking at the first few rows shows our data is, in fact, in tidy format:
tornado_df.head()
observation_year observation_month observation_date timezone \
0 1950 1 3 3
1 1950 1 3 3
2 1950 1 3 3
3 1950 1 13 3
4 1950 1 25 3
observation_state f_or_ef_scale starting_latitude_deg \
0 MO 3 38.77
1 IL 3 39.10
2 OH 1 40.88
3 AR 3 34.40
4 MO 2 37.60
starting_longitude_deg ending_latitude_deg ending_longitude_deg \
0 -90.22 38.83 -90.03
1 -89.30 39.12 -89.23
2 -84.58 0.00 0.00
3 -94.37 0.00 0.00
4 -90.68 37.63 -90.65
observation_datetime observation_valid_time
0 1950-01-03 11:00:00 1950-01-04 12:00:00
1 1950-01-03 11:55:00 1950-01-04 12:00:00
2 1950-01-03 16:00:00 1950-01-04 12:00:00
3 1950-01-13 05:25:00 1950-01-13 12:00:00
4 1950-01-25 19:30:00 1950-01-26 12:00:00
1. Cleaning Our Data
Unknown/non-CST timezones
The SPC data format doc mentioned some things to look out for in a few of the columns, one of the being that all reports should be in the CST time zone (regardless of the time of year), though some reports may not be listed as being in CST. First, we'll see how many different timezones we have in our dataset. A quick group-by operation shows we have 37 reports that aren't in CST (identified as 3). There are so few that aren't that we can just filter them out:
tornado_df.timezone.value_counts()
| timezone | num_reports |
|---|---|
| 3 | 63608 |
| 6 | 28 |
| 0 | 8 |
| 9 | 1 |
tornado_df = tornado_df.loc[tornado_df.timezone == 3]
Unknown F/EF scale
The SPC documentation also says -9 represents an "unknown" E/F Scale value. Taking the same approach, we can see the counts of each unique F/EF scale within our dataset. Given there are only 111 of these observations, we'll just filter them out:
tornado_df.f_or_ef_scale.value_counts()
| F/EF Scale | Number of Reports |
|---|---|
| 0 | 29712 |
| 1 | 21522 |
| 2 | 9208 |
| 3 | 2464 |
| 4 | 569 |
| -9 | 111 |
| 5 | 59 |
tornado_df = tornado_df.loc[tornado_df.f_or_ef_scale != -9]
2. Creating a "valid time" for each observation
As describe in the introductory post, we will be following SPC standards and create a model that predicts tornadic activity within a 12 UTC - 12 UTC time range. We'll refer to this as the "valid" time of our predictions/observations. However, our observation timestamps are all in the CST time zone, which is six hours behind UTC time. We'll need to do two thing:
- Convert our observations from CST to UTC.
- Assign each observation to the correct "valid" time.
The first part is easy enough, as we can just tack on six hours to our observation date/time stamps. To associate each observation with the correct valid time, we will use the following logic:
- Round each observation's date/timestamp up to the nearest 12th hour increment of each day.
- Any observation whose rounded timestamp has an hour equal to 0 will have 12 hours added on to the rounded timestamp.
pandas makes this operation super easy by incorporating round, floor, and ceil operations onto the timestamp objects:
tornado_df = tornado_df.assign(observation_valid_time=lambda x: (x.observation_datetime + pd.Timedelta('6H')).dt.ceil('12H'))
tornado_df = tornado_df.assign(observation_valid_time=lambda x: x.observation_valid_time.where(x.observation_valid_time.dt.hour != 0, x.observation_valid_time + pd.Timedelta('12H')))
| observation_datetime | observation_valid_time |
|---|---|
| 2018-12-20 11:28:00 | 2018-12-21 12:00:00 |
| 2018-12-20 16:10:00 | 2018-12-21 12:00:00 |
| 2018-12-26 15:40:00 | 2018-12-27 12:00:00 |
| 2018-12-26 16:23:00 | 2018-12-27 12:00:00 |
| 2018-12-27 06:12:00 | 2018-12-28 12:00:00 |
| 2018-12-27 10:15:00 | 2018-12-28 12:00:00 |
| 2018-12-27 10:29:00 | 2018-12-28 12:00:00 |
| 2018-12-31 12:35:00 | 2019-01-01 12:00:00 |
| 2018-12-31 13:43:00 | 2019-01-01 12:00:00 |
| 2018-12-31 14:38:00 | 2019-01-01 12:00:00 |
2. Exploring characteristics of the data
Spurrious Yearly Tornado Trends
Now that we've cleaned our data, we can start doing some exploratory data analysis. Since this dataset goes back to 1950, we may be interested in the number of tornado reports per year and how that's changed over time. We'll group by the observation_year column and count the number of observations within each year, and use seaborn to plot out the data with a trendline:
yearly_counts = (tornado_df.observation_year.value_counts().to_frame().reset_index(drop=False).rename(columns={'index': 'year', 'observation_year': 'number_of_reported_tornadoes'}))
g = sns.lmplot('year', 'number_of_reported_tornadoes', data=yearly_counts, height=5, aspect=2);
g.set(title='Number of Reported Tornadoes Per Year, 1950-2018', ylabel='Number of Reported Tornadoes');
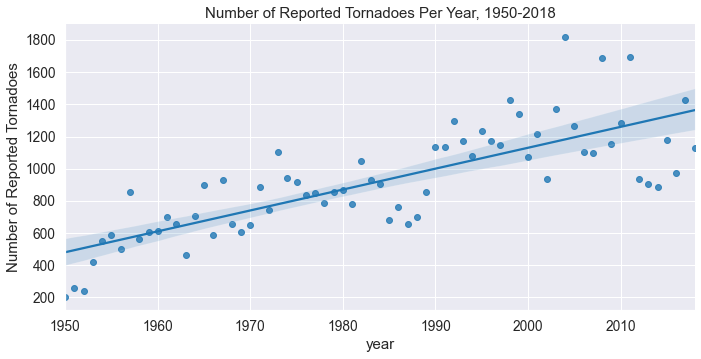
Looking at this plot, it sure looks like the total number of tornadoes per year have been increasing since 1950! That's a really interesting find, let's see if the same holds true for the number of tornadoes per year for each F/EF scale value:
yearly_ef_tornado_count = (tornado_df.groupby(['observation_year', 'f_or_ef_scale'])
.observation_valid_time
.agg(['count'])
.reset_index(drop=False)
.rename(columns={'count': 'number_of_reported_tornadoes'}))
g = sns.lmplot('observation_year', 'number_of_reported_tornadoes',
hue='f_or_ef_scale', data=yearly_ef_tornado_count, height=5, aspect=2);
g.set(title='Number of Reported Tornadoes Per Year by F/EF Scale, 1950-2018', ylabel='Number of Reported Tornadoes', xlabel='Year');
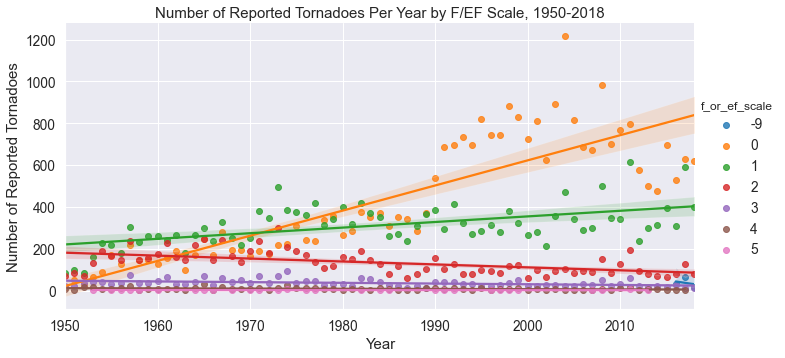
The above plot shows a flat trend for E/F 3, 4, and 5 tornadoes, a decreasing trend for E/F 2 tornadoes, a modest increasing trend for E/F 1 tornadoes, and an insane increasing trend for E/F 0 tornadoes. The specific datapoints on the plot show that this upward trend began around 1990, so what's the deal?
There's been some great research done on the topic of the quality of this historical tornado reports dataset, all of which I can't do justice to in this post. I'll attempt to summarize the causes of this spurrious trend described in greater detail in Doswell and Burgess (1988), Grazulis 1993, Brooks and Doswell (2001), and Verbout 2005:
- As the population increases and people move into formerly unpopulated regions, the number of tornadoes that occurred and were observed has increased.
- The popularity of storm chasing and the creation of storm spotting training sessions and network has likely resulted in an increase in tornado reporting.
- The NEXRAD Doppler radar network from NOAA has allowed for weaker tornado velocity signatures to be identified.
If we plot the timeseries of yearly tornadoes for each E/F Scale value from 1980 and also when the first Doppler radar was installed, we confirm that almost all of the upward trend of tornado reports is due to these E/F 0 reports:
_, ax = plt.subplots(figsize=(10, 5))
ef_tornado_count_since_1980 = yearly_ef_tornado_count.loc[yearly_ef_tornado_count.observation_year >= 1980].assign(f_or_ef_scale=lambda x: pd.Categorical(x.f_or_ef_scale))
ax = sns.lineplot('observation_year', 'number_of_reported_tornadoes',
hue='f_or_ef_scale', data=ef_tornado_count_since_1980, ax=ax);
ax.plot(np.ones(10) * 1990, np.arange(0, 1500, 150), '--k');
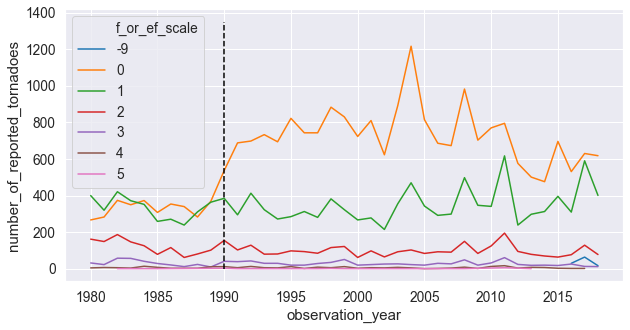
We have two options to account for this, neither of which is ideal:
- Keep only E/F 1 and greater tornadoes,
- Keep all tornadoes regardless of E/F scale, but only use data from 1990 to present.
We already have so few reports that it may be a bad idea to throw out all F/EF 0 tornadoes. That said, there may not be good signal for weaker tornadoes. As such, I ended up taking the first approach in my dissertation research. But, for funsies, we'll go ahead and take a mix of the two approaches: We'll only keep F/EF 1 and greater tornadoes and only use data from 1990 on:
tornado_df = tornado_df.loc[(tornado_df.observation_year >= 1990) & (tornado_df.f_or_ef_scale >= 1)]
Now, let's save this file as a csv and call it a day!
tornado_df.to_csv('../data/cleaned_tornado_reports.csv', index=False)
3. Amount of Time Taken
Unfortunately, I wasn't able to find the specific code I used to do this EDA the first time around, but I can tell you what I recall:
- I didn't use
pandasbecause I had no idea it existed. - I used built-in modules to parse the file as a CSV
- It took me probably a month or so to do this the first time, whereas this notebook took me about 20 or so minutes to put together.
Wow, 20 minutes! That would have provided me a lot more time to watch Major League and play Super Mario Kart do more research back in the day. We now have a (relatively) cleaned dataset of tornado reports! Let's say, instead of doing all of this within a Jupyter notebook, we wanted to run all of this data cleaning within a script, we ought to write functions to do this (something I definitely didn't do in grad school), so let's do that right now. This also can be used on the command line via click (which I've added to redissertation/data.py):
from typing import List, Dict
SPC_REPORT_RENAME_DICT = {'yr': 'observation_year', 'mo': 'observation_month',
'dy': 'observation_date', 'tz': 'timezone',
'st': 'observation_state', 'mag': 'f_or_ef_scale',
'slat': 'starting_latitude_deg',
'slon': 'starting_longitude_deg',
'elat': 'ending_latitude_deg',
'elon': 'ending_longitude_deg'}
def get_tornado_reports(url_or_path: str, date_and_time_columns: List[str]=['date', 'time'],
column_rename_and_keep_dict: Dict[str, str]=SPC_REPORT_RENAME_DICT) -> pd.DataFrame:
"""Get and preprocess SPC tornado reports data."""
df = (pd.read_csv(url_or_path,
parse_dates={'observation_datetime': date_and_time_columns})
.rename(columns=column_rename_and_keep_dict)
.loc[:, list(column_rename_and_keep_dict.values()) + ['observation_datetime',]])
return df
def drop_unknown_f_or_ef_scales(df: pd.DataFrame, f_or_ef_scale_column: str, unknown_scale_id: int=-9) -> pd.DataFrame:
"""Drop observations with unknown E/F Scale values."""
return df.loc[df[f_or_ef_scale_column] != unknown_scale_id].reset_index(drop=True)
def filter_by_year(df: pd.DataFrame, datetime_column: str, earliest_year_for_obs: int) -> pd.DataFrame:
"""Filter tornado reports data based on some start year."""
return df.loc[df[datetime_column].dt.year >= earliest_year_for_obs]
def find_valid_time(df: pd.DataFrame, observation_time_column: str,
valid_time_column: str='observation_valid_time') -> pd.DataFrame:
"""Match up observed tornadoes with a valid time (12z-12z).
Create the valid times of the reports, e.g. the "day" to which
they are associated. We consider the "valid time" to be the
ending time of a 24 hour forecast period. For example, a tornado
occurring at 2016-05-18 05:00Z would have a valid time of
2016-05-18 12:00Z, and a tornado occurring at 2016-05-18 15:00Z
would have a valid time of 2016-05-19 12:00Z.
"""
valid_times = (df.observation_datetime + pd.Timedelta('6H')).dt.ceil('12H')
valid_times = valid_times.where(valid_times.dt.hour != 0, valid_times + pd.Timedelta('12H'))
df = df.assign(**{valid_time_column: valid_times})
return df
def filter_non_central_time_reports(df: pd.DataFrame, timezone_column: str,
timezone_to_keep: int=3) -> pd.DataFrame:
"""Filter out tornado reports that weren't logged in CST."""
return df.loc[df[timezone_column] == timezone_to_keep]
def get_clean_and_save_tornado_reports(save_path, csv_save_name, spc_tor_url):
df = get_tornado_reports(spc_tor_url)
df = (df.pipe(drop_unknown_f_or_ef_scales, 'f_or_ef_scale')
.pipe(filter_non_central_time_reports, 'timezone')
.pipe(filter_by_year, 'observation_datetime', 1990)
.pipe(find_valid_time, 'observation_datetime'))
df.reset_index(drop=True).to_csv(os.path.join(save_path, csv_save_name), index=False)